ChatGPT est-il mauvais pour la planète ?
TL;DR - À retenir :
Constat : l’IA générative consomme de l’électricité et de l’eau, principalement via l’entraînement des modèles et le fonctionnement des data centers (notamment pour le refroidissement).
Ordres de grandeur : une requête typique se situe autour de 0,3 à 3 Wh, selon le modèle, l’infrastructure et la complexité de la tâche ; l’impact individuel reste modéré et souvent secondaire par rapport à d’autres postes comme le transport, le chauffage ou l’alimentation.
Enjeux : l’impact devient surtout collectif et structurel, dépendant notamment de la localisation des data centers, du mix électrique, du stress hydrique local, de la transparence des acteurs, ainsi que de la matérialité des infrastructures (GPU, serveurs, semi-conducteurs).
Actions : sobriété d’usage, meilleure mesure (PUE, WUE, scopes carbone, métriques d’efficacité), optimisation technique (modèles plus petits, cache, RAG), et encadrement réglementaire et industriel.
L’intelligence artificielle générative, comme ChatGPT, a émergé à une vitesse fulgurante. En à peine deux ans, elle est passée d’une curiosité technologique à un outil utilisé quotidiennement par des millions de personnes pour écrire, apprendre, programmer ou créer.
Mais cette révolution technologique soulève aussi des questions environnementales : faut-il s’inquiéter de son empreinte carbone, de sa consommation d’énergie et d’eau, ou encore de l’opacité des infrastructures qui la rendent possible ?
En bref : l’intelligence artificielle générative a-t-elle un coût écologique significatif, et si oui, à quel niveau se situe-t-il réellement : individuel, industriel ou politique ?
I – L’impact environnemental des IA en quelques chiffres
Même si la technologie est récente et complexe, l’impact environnemental de l’IA générative commence à être mieux mesuré. Il ne s’agit pas d’un monde purement virtuel : chaque requête, chaque entraînement de modèle nécessite de l’électricité, de la puissance de calcul, et souvent de l’eau pour refroidir les serveurs.
Une phrase à garder en tête : l’empreinte d’une IA dépend à la fois de l’infrastructure (data centers) et du modèle lui-même (taille, fréquence d’usage, méthode d’entraînement, efficacité).
Et au-delà de l’usage, la matérialité compte : GPU, serveurs et semi-conducteurs impliquent une ACV (analyse de cycle de vie), extraction, fabrication, transport, maintenance, et fin de vie (e-waste), qui s’ajoute aux impacts opérationnels.
À titre d’exemple :
Une requête dans ChatGPT consomme généralement entre 0,3 et 3 Wh, selon les estimations disponibles et les hypothèses retenues (modèle utilisé, longueur de la requête, infrastructure, et niveau d’optimisation).
Cela correspond à environ 0,2 à 3 grammes de CO₂ émis, selon le mix électrique et les hypothèses retenues.
Entraîner un grand modèle d’IA nécessite une puissance de calcul considérable, mobilisant des milliers de GPU (type de processeur spécialisé conçu pour effectuer un très grand nombre de calculs en parallèle) pendant des semaines ou des mois, ce qui représente une part importante de son empreinte environnementale totale, souvent concentrée lors de la phase initiale d’entraînement.
Autrement dit, le “coût” environnemental se joue souvent davantage dans l’entraînement, l’infrastructure et la montée en charge que dans une seule utilisation ponctuelle.
L’eau : un enjeu majeur
Le problème ne se limite pas à l’électricité : l’eau est aussi un enjeu majeur de l’IA.
D’après un rapport de Food & Water Watch (2025), les data centers aux États-Unis consomment des milliards de litres d’eau chaque année, parfois dans des zones touchées par la sécheresse. Or, l’essor de l’IA contribue à augmenter cette demande, dans un contexte où les usages réels et les lieux d’implantation restent souvent peu transparents.
Cette dimension hydrique est d’autant plus sensible qu’elle peut créer des tensions locales, en particulier dans les régions où l’eau est déjà une ressource sous pression.
C’est précisément ce que mesure (quand il est publié) un indicateur clé : le WUE (Water Usage Effectiveness), qui rapporte la consommation d’eau d’un data center à l’énergie utilisée par ses équipements informatiques.
Selon une étude de l’Université de Californie Riverside, Making AI Less Thirsty (2023), chaque kilowattheure d’électricité utilisé par un modèle d’IA peut entraîner indirectement la consommation d’environ 3,1 litres d’eau, principalement liée à la production d’électricité elle-même (Scope 2)*.
*Ces catégories viennent du GHG Protocol, la norme internationale utilisée pour mesurer les impacts environnementaux.
- Scope 1 : impacts directs (ex : combustion sur site)
- Scope 2 : impacts indirects liés à l’électricité consommée
- Scope 3 : impacts indirects liés à la fabrication, transport, fin de vie, etc.
À cela s’ajoute, selon les infrastructures, une consommation directe sur site pour le refroidissement, qui varie fortement selon la localisation, le climat et les technologies utilisées. Par exemple, certaines estimations indiquent environ 1 litre d’eau par kWh pour certains data centers opérés par Google, et jusqu’à environ 8 à 9 litres par kWh dans des conditions de forte chaleur, comme observé dans certaines régions des États-Unis.
En pratique, cela signifie que le lieu, la saison, le type de refroidissement et le mix électrique peuvent faire varier fortement l’empreinte hydrique d’un même usage.
Plus largement, cette variabilité reflète un point important souligné par Hannah Ritchie : l’impact environnemental d’une requête individuelle dépend fortement de facteurs invisibles pour l’utilisateur, comme la localisation du data center, son efficacité énergétique, et la source d’électricité utilisée. Cela explique pourquoi les estimations peuvent varier significativement d’un cas à l’autre, même pour une requête similaire.
L’énergie : PUE
Côté énergie, un autre indicateur central des infrastructures est le PUE (Power Usage Effectiveness), qui reflète l’efficacité énergétique globale d’un data center, en comparant l’énergie totale consommée par le site à celle effectivement utilisée par les équipements informatiques.
Cet indicateur est particulièrement important car, comme le souligne Hannah Ritchie, une part significative de l’énergie consommée par les systèmes d’IA provient non seulement du calcul lui-même, mais aussi de l’infrastructure nécessaire pour alimenter, refroidir et faire fonctionner les serveurs. L’efficacité globale du data center joue donc un rôle déterminant dans l’impact environnemental final.
Toutes les requêtes ne se valent pas
Enfin, il faut rappeler que toutes les requêtes ne se valent pas. Une tâche complexe peut consommer jusqu’à plusieurs dizaines de Wh, avec des estimations pouvant atteindre environ 40 Wh dans certains cas extrêmes, soit plus de 100 fois l’énergie d’une requête simple (Epoch AI, 2024).
Ces variations rendent difficile une évaluation unique et stable de l’impact de l’IA générative, et elles expliquent pourquoi les estimations peuvent sembler contradictoires selon les sources.
Hannah Ritchie souligne également que certaines estimations largement citées (comme 3 Wh par requête) reposent sur des hypothèses prudentes et des extrapolations, et pourraient surestimer l’impact réel dans certains cas. Des estimations plus récentes suggèrent qu’une requête simple pourrait consommer de l’ordre de 0,3 Wh, soit environ dix fois moins. Ces valeurs dépendent fortement du modèle utilisé, de l’infrastructure et de la complexité de la requête.
Cela illustre l’incertitude actuelle et l’importance d’interpréter ces chiffres comme des ordres de grandeur plutôt que comme des valeurs fixes.
Une bonne lecture consiste donc à raisonner en ordres de grandeur, plutôt qu’en chiffre “définitif”.
Méthodologie & hypothèses (à garder en tête en lisant les chiffres)
Périmètre carbone : distinguer Scope 2 (électricité achetée) et Scope 3 (matériel : fabrication GPU/serveurs, e-waste ; chaînes amont). La plupart des ordres de grandeur « par requête » couvrent principalement l’impact opérationnel (Scope 2) et sous-capturent les impacts liés à l’analyse de cycle de vie complète (ACV).
Type de requête : texte court vs longue conversation ; présence d’outils (recherche web, code, etc.) ; nombre de régénérations ; longueur de sortie. Ces facteurs influencent directement la quantité de calcul nécessaire et donc l’énergie consommée.
Modèle & fournisseur : taille et architecture du modèle, niveau d’optimisation (quantization, batching, cache), et politiques d’orchestration (par exemple, recours à des modèles plus petits lorsque cela suffit). Ces choix techniques peuvent fortement influencer l’empreinte énergétique par requête.
Localisation & période : mix électrique, température et saison (qui influencent les besoins de refroidissement), stress hydrique local, et moment d’exécution (l’intensité carbone du réseau électrique varie selon l’heure et la demande).
Infrastructures : efficacité énergétique du data center (PUE) et consommation d’eau (WUE), ainsi que le matériel utilisé (GPU, semi-conducteurs), leur durée de vie et leur renouvellement, qui contribuent à l’empreinte environnementale globale via l’ACV.
Comme le souligne Hannah Ritchie, l’un des principaux défis dans l’évaluation de l’impact environnemental de l’IA est le manque de transparence et de standardisation des données publiées par les entreprises. En l’absence de méthodologies uniformes et de données complètes, les estimations doivent être interprétées avec prudence, en tenant compte des hypothèses, des choix techniques et du contexte d’infrastructure.
II – Replacer ces chiffres dans leur contexte
Ces chiffres, pris isolément, peuvent impressionner. Mais ils doivent être replacés dans le contexte de la consommation individuelle, et surtout comparés à d’autres postes d’émissions.
L’essentiel est de distinguer deux échelles : l’impact marginal d’un utilisateur (faible) et l’impact cumulé de millions d’usages et d’une infrastructure en forte croissance (potentiellement significatif).
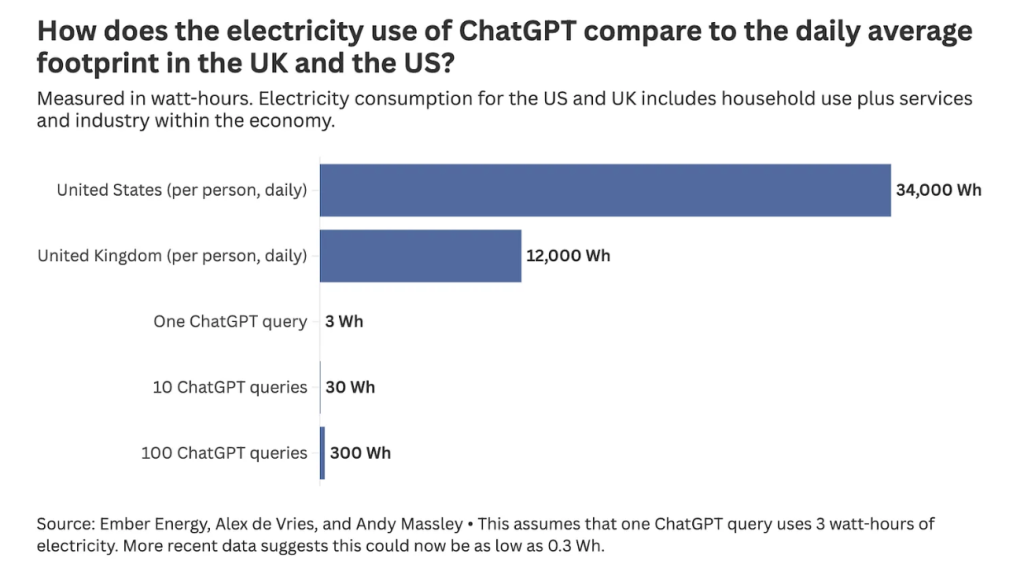
En prenant une hypothèse prudente d’environ 3 Wh par requête, un utilisateur qui interroge ChatGPT 10 fois par jour consommerait environ 0,2 % de sa consommation quotidienne d’électricité et représenterait environ 0,1 à 0,2 % de ses émissions personnelles de CO₂, selon les estimations présentées par Hannah Ritchie (Sustainability by Numbers, 2024).
Cela correspond également à une fraction extrêmement faible de la consommation annuelle d’électricité d’une personne, ce qui illustre à quel point l’impact d’une requête individuelle reste très faible à l’échelle d’un individu.
Cette comparaison montre que, pour un individu, la sobriété numérique compte, mais qu’elle ne remplace pas les leviers majeurs comme le transport, le chauffage ou l’alimentation.
Certaines estimations suggèrent que ChatGPT pourrait parfois ne consommer qu’environ 0,3 Wh par requête, soit à peine plus qu’une recherche classique (Epoch AI, 2024 ; Hannah Ritchie, 2024).
L’impact réel dépend donc largement de la tâche demandée, de la longueur des réponses, du modèle utilisé et des optimisations en production.
Comme le souligne Hannah Ritchie, même avec un usage intensif, par exemple 100 requêtes par jour, la part resterait modeste à l’échelle de la consommation électrique quotidienne individuelle, et nettement inférieure à celle des principaux postes énergétiques du quotidien.
À ce stade, la meilleure approche consiste à adopter des usages « utiles » (requêtes plus ciblées, moins de régénérations inutiles) plutôt qu’un arrêt total guidé par la culpabilité.
Pour donner un ordre de grandeur : 0,3 Wh correspond environ à ce qu’une ampoule LED consomme en environ 1 minute 30, ou à ce qu’un four électrique consomme en moins d’une demi-seconde.*
Un changement de certaines pratiques, comme l’utilisation de la voiture ou les choix alimentaires, a donc un impact environnemental bien plus important que l’arrêt de l’utilisation des IA, même si l’impact cumulé à l’échelle mondiale reste un enjeu industriel et politique.
Hannah Ritchie souligne également que, même sur une année entière, l’utilisation régulière de ChatGPT représente un ordre de grandeur de quelques kilogrammes à une dizaine de kilogrammes de CO₂ par an selon les hypothèses d’usage, ce qui reste extrêmement faible comparé aux émissions annuelles moyennes d’un individu, qui se comptent en plusieurs tonnes de CO₂.
* Une ampoule LED a une puissance entre 4 et 20 W, soit 12 W en moyenne. Elle consomme donc 0,3 Wh en 0,3 / 12 = 0,025 h = 1,5 min = 90 sec.
Même calcul pour un four électrique, qui a une puissance comprise entre 2000 et 3000 W : il consomme 0,3 Wh en 0,3 / 2500 = 0,00012 h = 0,432 sec.
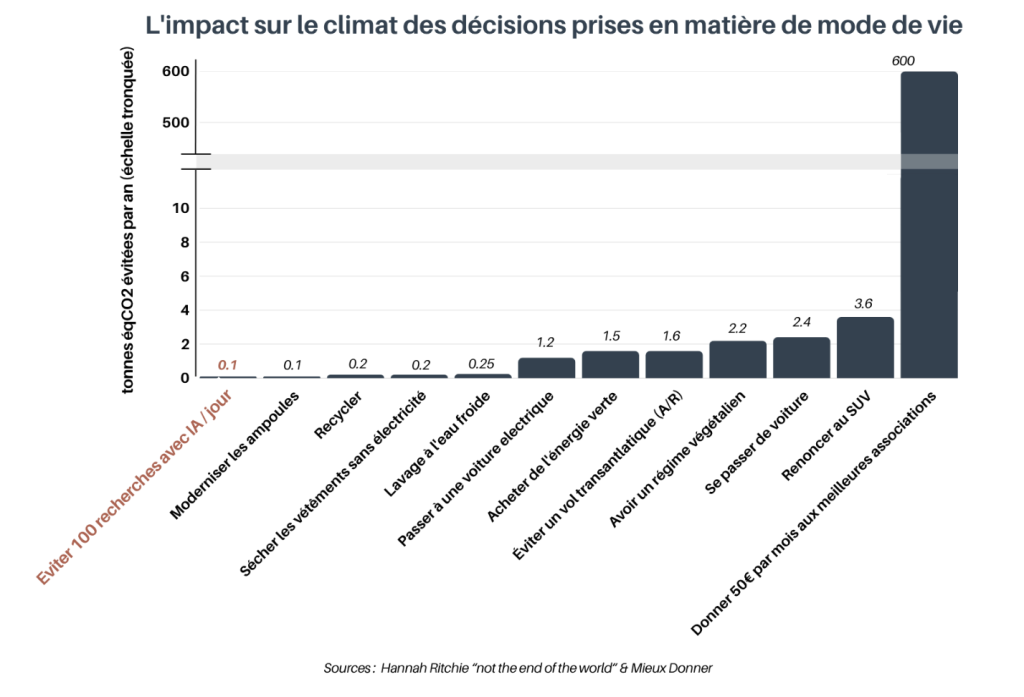
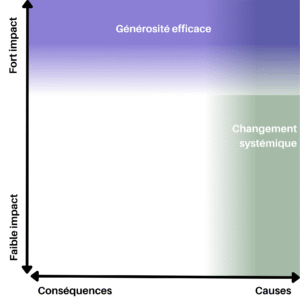
Ce graphe résume l’impact de plusieurs gestes pour réduire son empreinte carbone. Donner à des associations œuvrant pour des changements systémiques au sein de la politique environnementale et énergétique, telles que Clean Air Task Force ou Good Food Institute, peut avoir un impact climatique potentiellement bien supérieur à celui de la réduction de micro-usages individuels comme l’utilisation ponctuelle d’outils numériques, y compris l’IA.
L’idée clé est que l’effet de levier des actions collectives et structurelles dépasse largement l’optimisation de micro-usages individuels.
Certaines études, comme celle publiée dans Scientific Reports (2024), estiment que générer un texte ou une illustration via l’IA peut, dans certains cas, produire moins de CO₂ que des processus humains équivalents, notamment lorsque ces derniers impliquent un usage prolongé d’ordinateurs et d’infrastructures numériques.
Ce résultat dépend fortement des hypothèses (temps de travail, matériel utilisé, nombre d’itérations, type d’infrastructure), mais il rappelle un point important : l’empreinte environnementale n’est pas toujours intuitive, et l’IA peut parfois remplacer des processus plus énergivores.
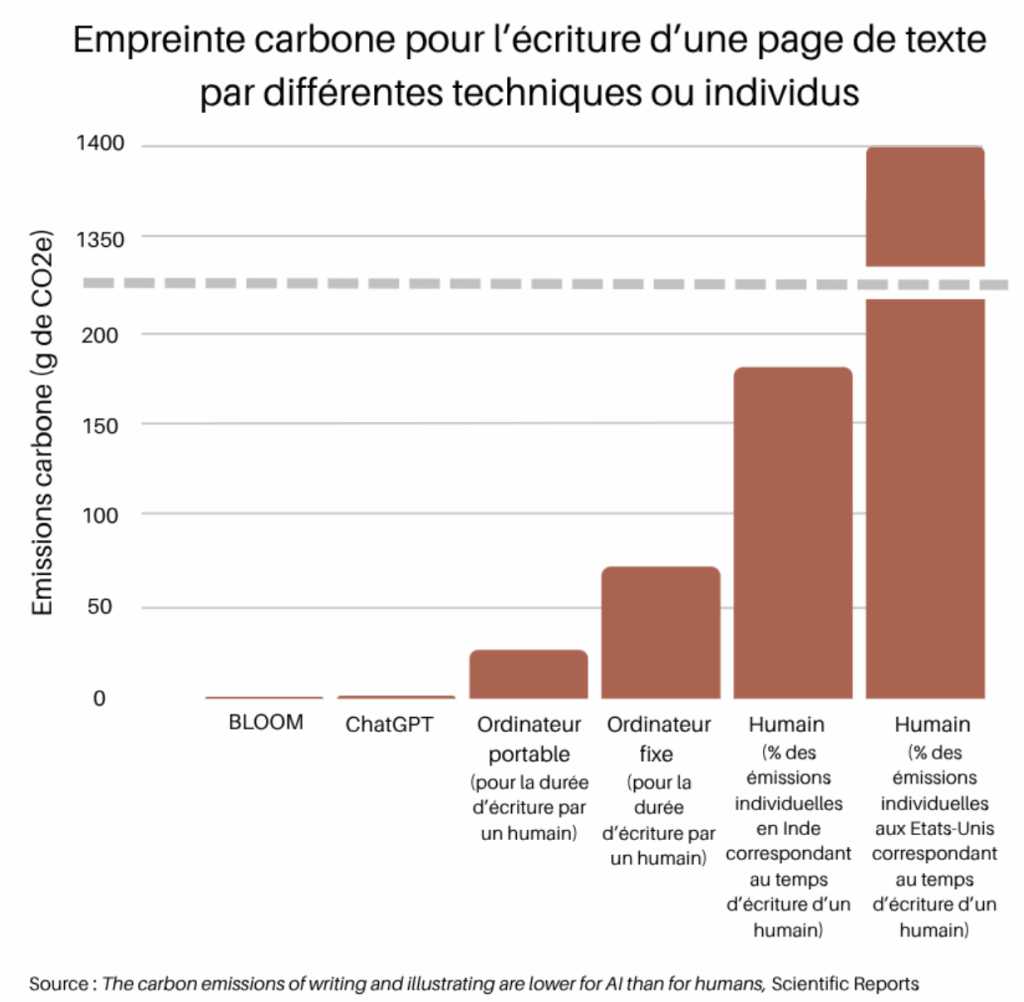
Cette figure compare les émissions de CO₂e de l’IA et des humains en charge de rédiger une page de texte. Selon l’étude (Scientific Reports, 2024), l’IA (via BLOOM ou ChatGPT) peut produire, dans certains cas, entre environ 130 et 1500 fois moins de CO₂e par page que des processus humains équivalents impliquant l’utilisation d’un ordinateur.
L’étude montre également que l’IA peut produire moins de CO₂et que l’utilisation prolongée d’un ordinateur pour rédiger un texte, en raison de la rapidité d’exécution et de la durée plus courte de mobilisation des ressources informatiques.
Même si les écarts exacts dépendent fortement des hypothèses (durée de travail, matériel, infrastructure, modèle utilisé), la tendance générale suggère que le “surcoût” écologique de l’IA n’est pas systématiquement supérieur à celui des alternatives numériques humaines.
Eau : ordres de grandeur
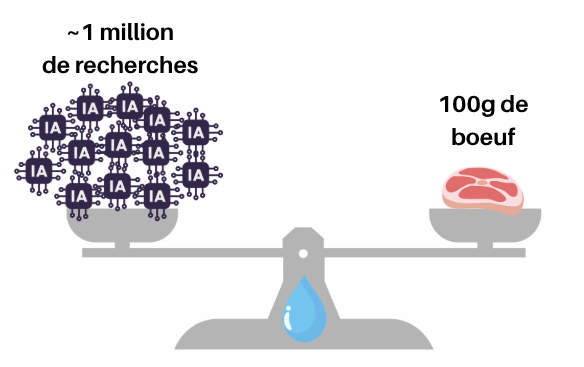
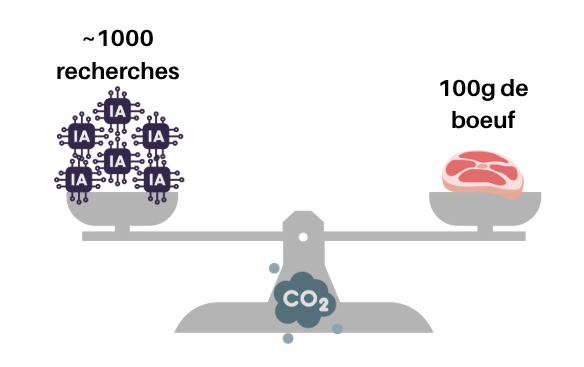
En ce qui concerne l’eau, certaines estimations suggèrent qu’une requête d’IA générative peut entraîner une consommation indirecte d’environ 7 à 47 ml d’eau, selon la localisation du data center, le mix électrique, et le système de refroidissement utilisé. Cette estimation inclut principalement l’eau utilisée pour la production d’électricité ainsi que, dans certains cas, le refroidissement des infrastructures.
En faisant 10 requêtes par jour pendant un an, cela représenterait un ordre de grandeur d’environ 25 à 170 litres d’eau, soit approximativement l’équivalent d’une douche à un bain, ou encore une fraction très faible de l’empreinte hydrique associée à des produits alimentaires comme le bœuf.
L’étude montre également que l’IA peut produire moins de CO₂et que l’utilisation prolongée d’un ordinateur pour rédiger un texte, en raison de la rapidité d’exécution et de la durée plus courte de mobilisation des ressources informatiques.
Même si les écarts exacts dépendent fortement des hypothèses (durée de travail, matériel, infrastructure, modèle utilisé), la tendance générale suggère que le « surcoût » écologique de l’IA n’est pas systématiquement supérieur à celui des alternatives numériques humaines.
Cette comparaison permet de remettre les ordres de grandeur en perspective. Elle repose sur une hypothèse d’environ 1 à 50 ml d’eau consommés indirectement par requête d’IA, principalement via la production d’électricité et le refroidissement des data centers (Li et al., 2023). À cette échelle, l’impact hydrique d’un usage individuel reste très faible : il faut ainsi plusieurs centaines de milliers à environ un million de requêtes pour atteindre l’empreinte hydrique d’un seul steak de bœuf de 100 g. L’enjeu principal se situe donc moins dans l’usage individuel ponctuel que dans l’impact cumulé des infrastructures à grande échelle.
III – Une technologie en évolution rapide
L’intelligence artificielle générative est encore une technologie jeune. Mais elle évolue vite, et des pistes concrètes émergent pour en réduire l’impact environnemental.
Il est probable que les gains d’efficacité (matériel, modèles, orchestration) jouent un rôle décisif, à condition qu’ils ne soient pas entièrement annulés par l’effet rebond (plus d’usages, plus de requêtes, plus d’automatisation).
Comme le souligne Hannah Ritchie, les systèmes informatiques, y compris les modèles d’IA, deviennent généralement plus efficaces avec le temps, grâce aux améliorations du matériel, des logiciels et de l’optimisation des infrastructures. Cela signifie que l’énergie consommée par requête pourrait diminuer à mesure que la technologie progresse, même si la consommation totale augmente avec l’adoption croissante de ces outils.
Certaines avancées techniques permettent déjà d’optimiser le moment ou le lieu d’exécution des requêtes afin de réduire leur empreinte énergétique, notamment en les alignant avec la disponibilité d’électricité bas carbone ou en améliorant l’efficacité des systèmes.
Une meilleure orchestration (choix du modèle le plus petit possible, cache, routage, optimisation des requêtes) peut aussi réduire fortement l’empreinte sans dégrader l’usage.
Des efforts sont également menés pour mieux mesurer et piloter l’impact hydrique des infrastructures, qui dépend du type de refroidissement, du mix électrique local, et de la localisation des data centers.
Ce suivi devient crucial car, selon le Lawrence Berkeley National Laboratory (2024), la consommation électrique des data centers pourrait augmenter fortement d’ici 2030 sous l’effet de la croissance de l’IA et des usages numériques, en l’absence d’améliorations majeures d’efficacité.
Sans métriques publiques et comparables, il reste difficile d’arbitrer entre performance, coût et sobriété. Dans cette logique, publier des indicateurs comme le PUE et le WUE, ainsi que leur évolution, permettrait de rendre les impacts mesurables et comparables.
Il faut aussi veiller à une meilleure répartition des impacts. Certains centres de données sont situés dans des régions où l’électricité est plus carbonée ou où l’eau est une ressource sous tension, ce qui peut déplacer les impacts environnementaux vers certaines zones géographiques.
La question n’est donc pas seulement « combien » l’IA consomme, mais aussi « où » et « dans quelles conditions » cette consommation a lieu.
Comme le souligne Hannah Ritchie, l’impact environnemental de l’IA dépend fortement de facteurs structurels tels que l’efficacité des data centers, le mix électrique et les choix d’infrastructure. Ces facteurs peuvent faire varier significativement l’empreinte réelle, indépendamment de l’usage individuel.
Matérialité : ACV du hardware, GPU et fin de vie (e-waste)
Une partie importante du débat écologique vient de la couche « invisible » : le hardware.
Les modèles d’IA générative reposent sur des flottes de GPU et de serveurs, donc sur une chaîne de valeur matérielle (semi-conducteurs) qui implique :
- extraction et transformation de ressources ;
- fabrication de composants et assemblage ;
- transport, installation et maintenance ;
- gestion de fin de vie (déchets électroniques, e-waste).
Dans une analyse de cycle de vie (ACV), l’impact environnemental ne se limite pas à l’électricité consommée pendant l’usage, mais inclut aussi les émissions et ressources mobilisées pour fabriquer, exploiter et renouveler les infrastructures.
À mesure que l’IA se généralise, la question de l’efficacité des infrastructures, de la durée de vie des équipements et de l’optimisation des ressources matérielles devient un levier important, au même titre que l’énergie et l’eau.
Ce point est cohérent avec l’analyse de Hannah Ritchie, qui souligne que l’impact environnemental des systèmes numériques, y compris l’IA, dépend non seulement de leur consommation directe d’énergie, mais aussi de l’infrastructure physique et énergétique qui les rend possibles.
Mais surtout, l’IA n’est pas seulement un problème environnemental : c’est aussi un levier.
D’après le Programme des Nations Unies pour l’Environnement (UNEP), l’intelligence artificielle peut déjà contribuer à :
- Mieux prédire les risques climatiques, les sécheresses ou les inondations ;
- Optimiser les réseaux de production et de distribution d’énergie ;
- Améliorer la surveillance environnementale grâce à l’analyse d’images satellites ;
- Identifier des sources de pollution ou de déforestation à grande échelle.
Ces applications ne sont pas sans coût environnemental, mais elles peuvent aussi contribuer à réduire les émissions ou améliorer l’efficacité des systèmes existants, notamment dans les domaines de l’énergie, de l’agriculture et de la gestion des ressources.
L’enjeu consiste donc en grande partie à orienter l’innovation vers des usages à bénéfice environnemental net positif.
Le Programme des Nations Unies pour l’Environnement souligne également que certains usages de l’IA pourraient augmenter la consommation d’énergie ou de ressources s’ils entraînent une augmentation globale des usages, notamment en raison d’effets rebond ou d’une automatisation accrue.
Par exemple, certaines applications comme les véhicules autonomes ou les systèmes numériques à forte intensité de calcul pourraient contribuer à une augmentation de la demande énergétique globale, selon la manière dont ils sont déployés.
Autrement dit, l’impact final dépend largement des choix technologiques, énergétiques et réglementaires qui accompagnent le développement de ces systèmes.
Ce point rejoint l’analyse de Hannah Ritchie, qui souligne que l’impact environnemental de l’IA dépend principalement de facteurs structurels comme le mix électrique, l’efficacité des infrastructures et les choix énergétiques, plutôt que des usages individuels isolés.
Il ne faut néanmoins pas négliger le fait que les IA comportent d’autres risques plus inquiétants, que le rapport international sur la sûreté de l’IA avancée a distingué en 3 grandes catégories :
- Les risques d’usage malveillant (préjudices liés à l’utilisation intentionnelle de l’IA pour nuire, comme la désinformation de masse ou le développement facilité d’armes biologiques)
- Les dysfonctionnements (dangers résultant d’un écart entre le fonctionnement attendu d’un système d’IA et son comportement réel tels que la perte de contrôle de futurs systèmes d’IA avancés)
- Les risques systémiques (diverses menaces engendrées par l’IA pour la société et l’environnement. qui incluent la destruction non-préparée d’emplois, l’aggravation des inégalités et la consommation excessive de ressources)
Nous nous concentrons ici sur les émissions liées aux requêtes adressées à des intelligences artificielles conversationnelles, comme ChatGPT, par des particuliers eux-mêmes. Or, une part importante des ressources de l’IA est aujourd’hui mobilisée par des fermes de contenus : inonder les fils YouTube, générer massivement des pages web ou produire des deepfakes, en photo comme en vidéo. La majorité de ces deepfakes sont d’ailleurs de nature pornographique et, malheureusement, réalisés sans le consentement des personnes dont l’image est utilisée.
Certaines associations que nous recommandons, comme le
CesIA ou le
Fonds pour la Préservation de l’Avenir, travaillent justement à mieux encadrer le développement de l’IA et à limiter les risques associés. C’est aussi là que se joue la responsabilité collective face à ces technologies émergentes.
France / UE : repères locaux (mix, data centers, reporting)
En France et dans l’UE, l’empreinte environnementale d’un usage d’IA dépend fortement du mix électrique et de la localisation des data centers, qui influencent directement les émissions associées à la consommation d’électricité ainsi que l’usage d’eau pour le refroidissement.
Comme le souligne Hannah Ritchie, l’impact environnemental d’une même requête peut varier significativement selon l’infrastructure utilisée, son efficacité énergétique, et la source d’électricité mobilisée.
Par ailleurs, le cadre européen renforce progressivement les exigences de transparence environnementale et de reporting pour les organisations, ce qui contribue à améliorer la disponibilité d’indicateurs liés à l’énergie, aux émissions et à l’efficacité des infrastructures numériques.
Dans ce contexte, les repères développés par des institutions comme l’ADEME, ainsi que les obligations de reporting environnemental au niveau européen, contribuent à améliorer la mesure, la comparabilité et la compréhension des impacts environnementaux du numérique et de l’IA.
Utiliser ChatGPT en toute conscience
L’usage de ChatGPT ou d’autres IA génératives n’est pas neutre sur le plan environnemental. Mais à ce jour, son impact reste très limité à l’échelle individuelle, et les perspectives d’optimisation sont réelles.
Comme le souligne Hannah Ritchie, même un usage régulier de ChatGPT représente une fraction extrêmement faible de la consommation énergétique et des émissions individuelles annuelles. À titre d’ordre de grandeur, même un usage quotidien peut représenter seulement quelques kilogrammes de CO₂ par an, ce qui reste très faible comparé aux émissions annuelles moyennes d’un individu.
Le cœur du sujet est donc de ne pas se tromper d’échelle : un usage raisonné a du sens, mais l’essentiel se joue surtout dans l’efficacité des infrastructures, le mix électrique utilisé, et les choix techniques des entreprises qui développent et exploitent ces systèmes.
Hannah Ritchie souligne en particulier que l’impact environnemental global dépend davantage de facteurs structurels, comme l’efficacité des data centers et les sources d’électricité, que des choix individuels isolés des utilisateurs.
L’important est donc de rester lucide, sans tomber dans une culpabilité contre-productive.
Utiliser ces outils de manière modérée, consciente et utile reste compatible avec une démarche écologique cohérente.
Avoir des ordres de grandeur en tête permet surtout d’éviter de surestimer l’impact de certains usages et de mieux identifier les actions réellement déterminantes pour réduire son empreinte environnementale.
Si vous souhaitez faire une réelle différence pour le climat, vous pouvez consulter notre page à ce propos.
Mesurer / vérifier son impact (check-list rapide)
Pour passer des débats généraux à quelque chose de vérifiable :
- Qualifier vos usages : texte court, conversation longue, génération d’images/vidéos, fréquence, régénérations.
- Estimer en plage : appliquer des fourchettes (ex. 0,3–3 Wh par requête « standard », plus pour tâches complexes) et compter le nombre d’actions sur une semaine.
- Demander les métriques (si entreprise/outil) : PUE, WUE, localisation (pays/région), mix électrique (ou intensité carbone), et périmètres couverts (Scope 2/3).
- Réduire à la source : prompts plus ciblés, limiter les itérations, éviter la génération « pour voir », et privilégier le modèle le plus petit qui suffit (quand c’est possible).
Ces approches sont cohérentes avec les recommandations générales issues des analyses comme celle de Hannah Ritchie, qui souligne l’importance de mieux mesurer et contextualiser les impacts plutôt que de se concentrer uniquement sur des estimations isolées.
Mini cas pratique chiffré : audit d’usage sur 7 jours
Sur 7 jours, vous faites 140 requêtes texte (≈ 20/jour) et 20 générations d’images.
Hypothèses prudentes : 1 Wh par requête texte en moyenne (ordre de grandeur intermédiaire cohérent avec les estimations disponibles, généralement comprises entre environ 0,3 et 3 Wh) et 10 Wh par image (hypothèse illustrative plausible, la génération d’images nécessitant généralement davantage de calcul que le texte).
Calcul : 140 × 1 Wh = 140 Wh ; 20 × 10 Wh = 200 Wh ; total = 340 Wh sur 7 jours, soit 0,34 kWh.
Même en doublant ces hypothèses, on reste sur un ordre de grandeur modeste à l’échelle individuelle. À titre de comparaison, cela correspond à moins d’un kilowattheure par semaine, soit une fraction très faible de la consommation électrique hebdomadaire d’un foyer.
L’intérêt principal de cet exercice est d’identifier où se concentrent les usages, qui sont souvent dominés par les tâches les plus intensives en calcul, comme la génération d’images, de vidéo ou les longues conversations.
Cet ordre de grandeur est cohérent avec les analyses disponibles, notamment celles de Hannah Ritchie, qui montrent que l’impact énergétique individuel de l’usage courant de l’IA générative reste faible comparé à d’autres postes énergétiques du quotidien.
Calcul : 140 × 1 Wh = 140 Wh ; 20 × 10 Wh = 200 Wh ; total = 340 Wh sur 7 jours, soit 0,34 kWh.
FAQ
Une requête ChatGPT pollue-t-elle plus qu’une recherche Google ?
En moyenne, oui selon plusieurs estimations, mais l’écart dépend beaucoup de la complexité de la tâche, du modèle et des optimisations en production. Hannah Ritchie souligne également que ces estimations varient fortement selon les hypothèses et doivent être interprétées avec prudence.
L’IA consomme-t-elle surtout de l’électricité ou de l’eau ?
Les deux : l’électricité alimente le calcul, et l’eau intervient directement et indirectement. L’impact dépend fortement de l’infrastructure utilisée.
Dois-je arrêter d’utiliser les IA pour être écologique ?
Pour un usage individuel modéré, l’impact est généralement faible comparé à d’autres postes. Hannah Ritchie souligne que les principaux leviers de réduction des émissions à l’échelle systémique se situent ailleurs, notamment dans les systèmes énergétiques et les infrastructures.
Pourquoi l’impact varie autant selon les études ?
Parce que les hypothèses changent : taille du modèle, infrastructure, localisation, et méthodologie. Le manque de transparence contribue également à ces incertitudes.
Comment réduire concrètement l’impact environnemental de l’IA ?
À l’échelle individuelle : optimiser ses usages. À l’échelle collective : améliorer l’efficacité énergétique, le mix électrique et la transparence.
Un long chat texte consomme-t-il plus que plusieurs requêtes courtes ?
Souvent oui, car le traitement dépend du volume de contexte.
Que signifient PUE et WUE (et pourquoi c’est important) ?
Ils mesurent l’efficacité énergétique et hydrique des data centers.
Quelles actions concrètes côté entreprise ?
Optimisation des modèles, infrastructure plus efficace, transparence et mesure.
Ces leviers correspondent aux facteurs structurels identifiés par Hannah Ritchie comme déterminants pour l’impact environnemental réel de l’IA.